FADO: A Deterministic Detection/Learning Algorithm
This research explores how to deal with detection in a deterministic (worst-case) way. That is, is there a deterministic alternative to the stochastic approach of statistical hypothesis testing and density estimation?
We derive an algorithm - dubbed FADO (Online FAult Detection) - and give theoretical justifications for its detection capability.
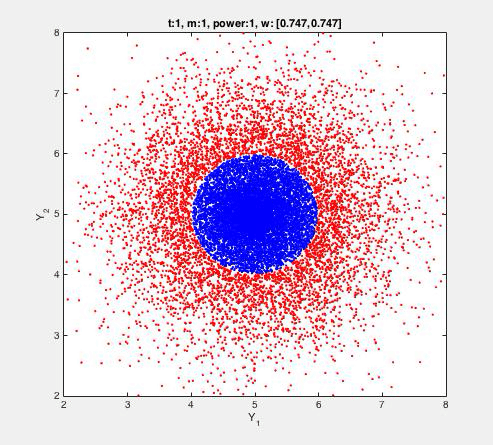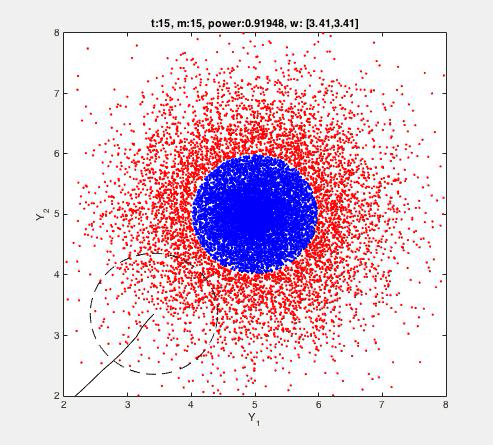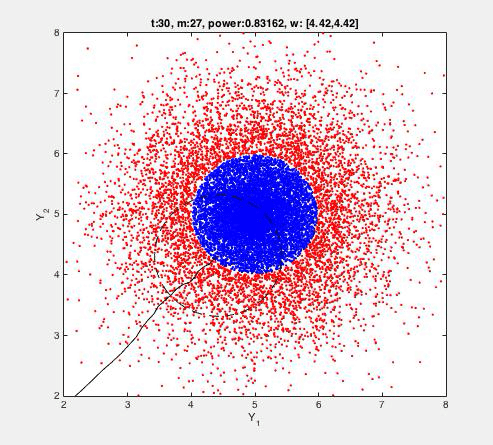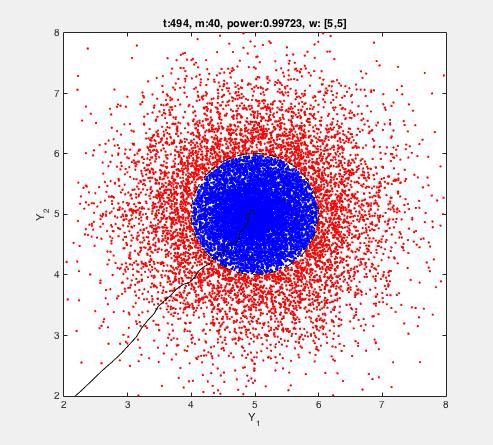
The FADO algorithm is applied to an artificial 2D dataset as described and visualised below. Detection is done by the following rule:
||yt - wt-1||2 < e
where e>0 is fixed/given (here e=1), and wt-1 is learned. The algorithm is mistake-driven, meaning that every time a fault is detected (i.e. ||yt - wt-1||2 > e), the vector wt-1 (and hence the detection rule) is also updated ('learned'). That is, alarms (mistakes) drive further learning, so that nothing changes whenever the rule works well. The T=10.000 blue dots {yt}t are normal transactions given to the algorithm. The 20.000 red dots denote atypical transactions, not given to the algorithm, but which we'd hope to detect. 'Power' denotes the fraction of red dots indeed detected by the learned rule. For example, a power=1 indicates that all of the red dots are detected as faulty, indicating a perfect detection rule. The number m denotes the number of alarms raised by the algorithm. Since in this case the blue dots can be perfectly separated from the red dots, those alarms are necessarily false. In this case, only a fraction of 40/10000 (0.4%) is used to learn from. The centre of the blue circle is at (5,5). This position is recovered after t=494 instances: only m=40 (false) detections and the consequent updates were present in this period. This algorithm excels by (1) it's (computational) simplicity, (2) robustness, and (3) scalability.
The following example is based on the pioneering work of E.Muybridge (1830-1904). A 400x400 video was composed of 15 clips of animal locomotion. The FADO algorithm was applied without much tuning to the resulting data-stream consisting of 3330 frames, in order to detect novel scenes.

This still - taken from the video - has two panels: the left one is the original frame y99 at time instance t=99, the right one displays the memory w98 which was used in this case. Whenever the scene transits, the memory does not capture the new frame quite well, resulting in a detection and a consequent update. The frame-number t is displayed in the left panel. In the video, the upper-part of the left panel colors red (green) in case of such a detection/learning at t. Note that the memory adapts nicely to the new scenes.
These cases are detailed in the companion paper.