
|
Programmeringsfel på Mars.
Mars Pathfinder landade på Mars 4 juli 1997. I dag har den slocknat, efter månader i tjänst (se F&F 1/98). Men det höll på att sluta redan direkt efter landningen. Efter några dagar krånglade datorn ombord. Den hängde sig och var tvungen att bli omstartad flera gånger; värdefulla mätningar förlorades. Anledningen var ett programmeringsfel. Ett läge uppkom där två delprogram samtidigt försökte utnyttja samma del av datorn. Trots en omfattande testning innan start hade ingen förutsett detta. Lyckligtvis kunde teknikerna omprogrammera datorn från jorden så att felet försvann.
|
|
En rimligare förklaring är att informationsteknologin behandlar immateriella konstruktioner som inte låter sig beskrivas med välkända mekaniska egenskaper, som krafter, vridmoment och friktion. Så vad menas exakt med en dators ”beteende” och hur kan det göras begripligt? Det är vanligt att man försöker tänka materiellt: knappar trycks in, lampor tänds, signaler åker genom ledningar. Eller mänskligt: datorn tror, maskinen vill, systemet surar. Men de materiella liknelserna är för begränsade och de mänskliga för vaga för att vara ritningsunderlag. I vanliga ingenjörsdiscipliner sätter materien en gräns för storlek och uppbyggnad. Datorsystemens beteenden begränsas däremot bara av programmerarnas uppfinningsrikedom.
|
|
Automatisk verifiering
|
|
Om ett program ska kunna utsättas för helt automatisk analys får det inte vara för stort, eftersom beräkningarna annars tar för lång tid. En vanlig automatisk analysmetod är nämligen att gå igenom alla tillstånd som programmet kan anta.
System som undviker omfattande numeriska beräkningar kan ofta testas utan att antalet tillstånd blir ohanterligt. Flera datorprogram klarar i dag av automatiska analyser av miljontals tillstånd.
|
Exempelvis kan nämnas SPIN, från AT&T, som framgångsrikt använts bland annat vid utvecklingen av telefonväxlar. Vid Carnegie Mellon University har man nyligen med ett annat program automatiskt kontrollerat en datorkrets för division av tal bestående av 64 bitar (tal med 19 siffror). Analysmetoderna bygger på listiga sätt att representera stora mängder tillstånd.
|
|
Språk som inte talas
För att beskriva beteenden utgår man dels från viktiga händelser, t ex ”förbindelsen kopplas upp”, ”värdet beräknas”, dels från tillstånd, t ex ”klar att ta emot data”, ”förbindelsen är uppkopplad”. Ett beteende är då möjliga följder av händelser och tillstånd. Det kräver dock viss omsorg att göra beskrivningar som inte kan missförstås.
|
uppkoppling
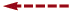
|
|
inte uppkopplad
|
uppkopplad
|
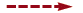
nedkoppling
|
|
Om vi tar två viktiga typer av händelser i ett datanät: ”förbindelsen kopplas upp” och ”förbindelsen kopplas ner”, kanske vi vill beskriva att först måste uppkoppling ske, därefter nedkoppling, därefter möjligen uppkoppling följd av nedkoppling osv. Hur ska vi beskriva det helt entydigt? Beskrivningen kanske tycks enkel och klar, men vad är den exakta innebörden av orden ”möjligen” och ”osv”?
|
|
Att ge förklaringar av detta slag på svenska (eller något annat naturligt förekommande språk) är hopplöst eftersom varje försök att definiera ett begrepp kräver nya ord som i sin tur ska förklaras. Förklaringarna bottnar aldrig i helt väldefinierade begrepp.
Lösningen är att använda s k formella språk. Dessa är inte språk i ordets vanliga mening, eftersom det som kan uttryckas på formella språk är starkt begränsat. Till exempel går det inte att säga ”var snäll och köp lite mjölk på hemvägen”. Begrepp som ”lite” och framför allt ”snäll” är det ingen som har vågat försöka definiera matematiskt. Däremot går det bra med ”uppkoppling och nedkoppling alternerar”. I formella språk är betydelsen av utsagor definierade med matematisk noggrannhet. Man har minskat uttrycksfullheten för att vinna i precision.
Ett exempel på formella språk är s k tillståndsdiagram (bild 3). I bild kan man beskriva händelserna utan att det blir tvetydigt.
Det finns massor av formella språk trots att antalet principer för att beskriva beteenden inte är stort. IT-företagen har helt enkelt ännu inte kunnat enas om en standard. Det är föga troligt att de kommer att göra det inom en snar framtid – inte heller kommer de att enas om att använda ett enda programmeringsspråk.
|
Skriv först – prova sedan
I datorernas barndom var minnet mycket litet och programmen följaktligen små och få. Programmerarna satte en ära i att hålla hela system i huvudet och rättade programfel, eller dödade löss som man sa, genom att tänka djupt och länge. I dag innehåller den enklaste persondator miljontals programinstruktioner men fortfarande försöker vi avlusa genom intellektuella maratonlopp. Oftast skriver vi dessutom snabbt ihop ett program och försöker kompensera bristen på planering med en grundlig utprovning. Men tidiga flygturer kan lätt sluta i Gripen-gropen.
|
Funktionsfel kan inte förutsägas, och när de yttrar sig i den lakoniska dödsrosslingen ”system error” blir det ett styvt jobb att spåra orsaken och ett sisyfosarbete att åtgärda den, eftersom varje förändring kan rubba andra delar av systemet. Ingenjören, å sin sida, använder matematiska modeller för att räkna ut viktiga egenskaper hos det som ännu inte är byggt.
|
|
Om ett kugghjul blir för klent upptäcks detta redan i modellen och man kan ändra konstruktionen. På samma sätt vill en programmerare kunna analysera en modell av ett beteende för att säkerställa att det är acceptabelt. Allra bäst vore det om det fanns en möjlighet att också garantera att modellen är riktig.
Här stöter vi dock på patrull. För det mesta saknas metoder som garanterat ger ett korrekt svar. Det finns till och med bevis för att sådana metoder inte kan finnas. Detta visade den brittiske matematikern Alan Turing redan 1936 (se F&F 4/97). Vi kommer aldrig att kunna få allmänna metoder som svarar på frågor som: Uppfyller systemet ett visst krav? Kommer systemet någonsin att slutföra beräkningen? Har två system samma beteende? Är två krav motstridiga?
Listan kan göras lång, och det är lika illa för alla formella språk. Att leta efter allmängiltiga metoder för att svara på sådana frågor är lönlöst. Vi måste hålla till godo med metoder som bara fungerar i vissa speciella fall.
Tre vägar har hittills prövats för att komma till rätta med det problemet. Den första innebär att man minskar språkets uttrycksmöjligheter. Om möjligheterna beskärs tillräckligt kraftigt kan frågorna avgöras. Till exempel kan man bestämma en övre gräns för hur stora de tal får vara som datorn kan behandla.
Då går det inte längre att direkt uttala sig om godtyckligt stora tal. En sådan inskränkning kan tyckas harmlös, men har faktiskt stor betydelse i många sammanhang. Ta t ex division av heltal. Skriver man ett program som ska dividera vill man gärna veta att det fungerar för alla heltal, dvs för en oändlig mängd olika tal. I och för sig har varje dator en övre gräns för hur stora tal som kan behandlas, men eftersom dessa gränser är olika för olika datorer är det olyckligt om programmets riktighet är beroende av en sådan inskränkning. Dessutom går det inte att förutsäga vilka uppgifter som kommer att matas in i ett program. Sådana spådomar kommer oftast på skam; därför vill man hellre säkerställa att det fungerar i alla väder. Annars kan det gå som för Ariane 5 där styrdatorn havererade när ett delprogram tog emot ett oväntat och otillåtet stort värde.
Ett tal långt som åtta böcker
En annan svårighet är att även om frågorna med denna inskränkning går att besvara teoretiskt, så är det tyvärr inte säkert att metoderna är praktiskt genomförbara. En dator med ett minne på 16 megabyte kan befinna sig i fler olika tillstånd än 10 upphöjt till 40 000 000, ett tal som är så stort att det tar upp åtta band av Nationalencyklopedin om man skriver ut det. Fortfarande är det ett ändligt antal, men en metod som måste pröva alla dessa tillstånd är dödsdömd ur praktisk synvinkel, även om den i princip fungerar.
|
|
Programmeringsfel drabbade Kasparov.
När schackdatorn Deep Blue mötte och besegrade världsmästaren Garri Kasparov var det kanske ett datorfel som avgjorde matchen. I andra partiet av sex missade schackdatorn att det fanns en möjlighet till remi. När Kasparov efter matchen upptäckte att datorn missat tyckte han sig se att datorn gjort ett mänskligt fel och detta bidrog till hans misstankar att matchen inte var helt juste (se F&F 6/97). Men att Deep Blue missade chansen till remi förklarar upphovsmännen med en programmeringsmiss. Ett mänskligt fel, visserligen, men inte det som Kasparov avsåg.
|

|
Forskningen arbetar därför inom två områden. Det ena söker möjligheter att göra beskrivningar där tillståndsdiagrammen och datamängderna inte bara är ändliga utan också ganska små. Man gör det genom att utesluta onödig information och genom att dela upp beskrivningarna i hanterbara delar. Det andra området är att utveckla metoder som effektivt kan hantera allt fler tillstånd. I dagsläget är det möjligt att, med datorns hjälp, uttömmande analysera uppemot en miljon tillstånd. Vissa metoder kan nå ännu bättre resultat när det gäller speciella problem.
En annan väg att undvika olösliga problem är att ställa frågor som inte direkt rör hur datorn kommer att bete sig. I stället kan man kontrollera om programmen är riktigt uppbyggda till sin struktur. Även om detta i och för sig inte garanterar riktiga beteenden så visar erfarenheten att ett stort antal fel avslöjas vid sådana kontroller.
|
|
Man kan systematiskt kontrollera att växelverkan mellan systemets olika delar följer etablerade mönster, att begrepp som ingår ges ordentliga definitioner, att inga uppenbart onödiga delar finns osv.
Typkontroll hade räddat Ariane
Ett bra exempel på detta är den så kallade typkontroll som finns för många moderna programmeringsspråk. Om det t ex någonstans står att innehållet i en variabel ska ökas med ett, är det rimligt att anta att variabeln måste innehålla ett tal. Om det å andra sidan står att man ska ta första bokstaven i variabeln, bör den innehålla en text. På detta sätt kan man klassificera data i olika typer utifrån sättet som de används på och kontrollera att samma datavärde inte förutsätts ha motstridiga typer på olika ställen av beskrivningen. Haveriet med Ariane 5 skulle ha undvikits om en sådan kontroll hade gjorts av styrprogrammet.
En tredje väg består i att acceptera ofullständiga analysmetoder. Det finns metoder där man vet att svaren man får är korrekta, men som inte alltid ger något svar alls. Dessa metoder är inte begränsade av antalet tillstånd.
Dessa ofullständiga metoder är baserade på formell logik, och principen är att hitta bevis i speciella logiska skrivsätt. Om man hittar ett bevis är frågan avgjord. Om inte, kan detta bero antingen på att det inte finns något bevis, eller på att det finns men att man har misslyckats med att hitta det. Det är omöjligt att veta vilket av de två senare alternativen som föreligger.
En fullständig automatisering av sådana metoder är inte att rekommendera med dagens teknologi. När det gäller att leta efter bevis behövs listighet, förmåga att se mönster och allmän erfarenhet. Detta kan man träna ingenjörer till, men det är svårt att programmera datorer att göra det bra. Dessutom är resultatet av en bevisföring ofta mer än det summariska ”utsagan är sann”; man kan i arbetet med att ta fram beviset få en intuitiv insikt om orsakerna. Denna kan vara värdefull i många sammanhang, men är svår att skapa i en dator.
|
Ett bevis kan kontrolleras
En fullständig bevisföring blir till sin längd jämförbar med den beskrivning som analyseras, eller ofta till och med ännu längre. Det kan lika gärna uppstå ett fel i själva bevisföringen som i programmet som ska kontrolleras. Om sannolikheten att ett misstag begås är proportionell mot längden, är alltså mycket litet vunnet! Skillnaden är dock att ett bevis, men inte ett program, kan kontrolleras på ett mekaniskt sätt. Så även om datorer inte själva kan utföra bevisen kan de i efterhand kontrollera att bevisen är riktiga. Det finns i dag flera program för detta och till och med program som hjälper till litet under arbetet med bevisföringen. Forskningen på området har utvecklats mycket starkt de senaste tio åren och utgör i dag en stor del av datalogisk forskning överhuvudtaget.
|

|
Fel i processorn.
I oktober 1994 upptäcktes att Pentium, den processor som i dag finns i 85 procent av alla persondatorer, räknade fel. Felet uppträdde så sällan att en normalanvändare antagligen aldrig skulle påverkas, men Intel tvingades ändå byta ut miljontals felaktiga chips.
|
|
Först de senaste åren har resultaten börjat visa sig. I modern systemutveckling vill man ha en begriplig struktur för både form och funktion. Nya språk tvingar programmerarna att ange hur olika programdelar kan kombineras för att undvika att de sätts ihop på fel sätt. Vid säkerhetskritiska tillämpningar i kärnkraftverk krävs en logisk analys som bevisar att beteendet är acceptabelt. Men övergången från kaotisk till välordnad produktion är inte smärtfri. Den inskränker ju friheten för alla våra dataexperter och programmeringsfantomer.
|
Logiska korrekthetsbevis
|
|
Vid SRI, ett privat forskningsinstitut i Stanford, utvecklar man sedan 15 år PVS, Prototype Verification System, där bevisföringar kan formuleras och kontrolleras. Hade Intel använt en sådan teknik skulle felaktigheten i de första Pentiumprocessorerna förmodligen ha avslöjats innan de byggts.
Nackdelarna med en sådan metod är att notationen är svårgenomtränglig och bevisstegen många.
|
Detta gäller även mer industriellt anpassade system, som exempelvis B-metoden. Den blev berömd när järnvägssignalerna för pendeltågen i Paris programmerades om för att öka tågtätheten i slutet av 1980-talet. Nio tusen rader kod analyserades logiskt för att bevisa riktigheten hos kritiska delar. Den ansvariga myndigheten i Paris krävde en sådan analys innan systemet fick tas i drift.
|
|
|

© Forskning & Framsteg
Frågor ställs till Patric Hadenius, PH@fof.se
|
|


