A sample intersection
There are actually three activities that take place in the "two phase" update algorithm:
Two phase locking prevents deadlock from occuring in distributed systems by releasing all the resources it has acquired, if it is not possible to obtain all the resources required without waiting for another process to finish using a lock. This means that no process is ever in a state where it is holding some shared resources, and waiting for another process to release a shared resource which it requires. This means that deadlock cannot occur due to resource contention.
The resource (or lock) acquisition phase of a "two phase" shared data access protocol is usually implemented as a loop within which all the locks required to access the shared data are acquired one by one. If any lock is not acquired on the first attempt the algorithm gives up all the locks it had previously been able to get, and starts to try to get all the locks again.
This "back-off and re-try" strategy can be a problem in distributed systems. It is not guaranteed to give access to the desired resources within a finite time. This can lead to process starvation, if a single process never acquires all the locks needed for it to continue exectuion. This is a problem for real-time systems. Consequently, two phase locking protocols cannot be used in hard realtime applications.
In addition, more complicated problems arise when two processes compete over locks in such a way that the pattern of back-off and re-try attempts always leads them to conflict over locks in a sequence that means that neither process will ever get all the locks it needs to commit a transaction. One way to prevent this from happening is to order the locks in a global sequence, and require the processes to acquire the locks in that sequence, then both livelock and deadlock are eliminated from the algorithm.
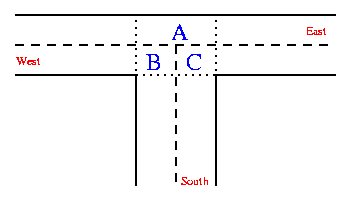
Consider the example where processes gain access to the shared space in a traffic intersection using semaphores that represent ownership of spaces in the intersection. Each car has two possible direction choices as it enters the intersection and the algorithms executed by cars entering the intersection from different directions are shown in the following table. Refer to the picture for and image of the intersection and the allocation of compass points and semphores to areas.
A set of access algorithms that uses incremental locking and allows deadlock.
| Car from South | Car from West | Car from East |
Go_East:
Wait(C)
Turn_Right
Signal(C)
Go_West:
Wait(C)
Wait(A)
Turn_Left
Signal(A)
Signal(C)
|
Go_East:
Wait(B)
Wait(C)
Drive_Straight
Signal(C)
Signal(B)
Go_South:
Wait(B)
Turn_Right
Signal(B)
|
Go_West:
Wait(A)
Drive_Straight
Signal(A)
Go_South:
Wait(A)
Wait(B)
Turn_Left
Signal(B)
Signal(A)
|
A set of access algorithms that uses incremental locking and prevents deadlock.
| Car from South | Car from West | Car from East |
Go_East:
Wait(C)
Turn_Right
Signal(C)
Go_West:
Wait(A)
Wait(C)
Turn_Left
Signal(A)
Signal(C)
|
Go_East:
Wait(B)
Wait(C)
Drive_Straight
Signal(B)
Signal(C)
Go_South:
Wait(B)
Turn_Right
Signal(B)
|
Go_West:
Wait(A)
Drive_Straight
Signal(A)
Go_South:
Wait(A)
Wait(B)
Turn_Left
Signal(B)
Signal(A)
|
The only way that a two phase commit can be implemented safely is for each of the replicas to have some knowledge of where all the participating entites are in the process of updating the shared information. If each of the entities keeps a diary of what it has been doing then they can crash and re-start without becomming confused, or allowing inconsistent data states to develop. Again, two phases are used,
Your initial test of a commit process can be conducted using simple processes which implement only the basic algorithm and only update the log files with appropriate messages. This means that you can test the protocol without having to worry about the updates on the back-end databases initially. Once you have a working protocol then you can add in the operations to change the data in the back-end database servers.